13. Reliability Plots
13.1. Description
Reliability (or attributes) diagrams are used to show the conditional bias of probabilistic forecasts. If a probability forecast is reliable, then the relative frequency of events for a certain category of probability forecasts will be approximately the same as the forecast probability. In other words, when a 50% probability of precipitation is forecast, approximately half of the corresponding observations should indicate that precipitation fell.
The reliability diagram groups the forecasts into bins according to the issued probability (x axis). The frequency with which the event was observed to occur for this sub-group of forecasts is then plotted against the y axis. For perfect reliability the forecast probability and the frequency of occurrence should be equal, and the plotted points should lie on the diagonal (by default a solid grey line in the example figure below). In other words, when a 50% probability of precipitation is forecast, approximately half of the corresponding observations should indicate that precipitation fell.
Reliability diagrams can be used to make adjustments to the conditional bias of the forecast probabilities.
13.2. Line Type
Reliability diagrams require the probability statistics (PCT line type) generated by either Point-Stat or Grid-Stat.
13.3. How-To
Selection of options to produce the reliability diagram proceeds approximately counter-clockwise around the METviewer window.
Select the desired database from the “Select databases” pulldown menu at the top margin of the METviewer window.
There are a number of tabs just under the database pulldown menu. Select the ‘Rely’ tab.
Select the desired series variable to calculate statistics for in the “Series Variables” tab. Press the “+ Series Variable” button to reveal two pulldown menus. The first pulldown menu in the lists the categories available in the selected dataset. The second pulldown menu allows the selection of the value of that category. The reliability diagram only makes sense for probability forecasts. These can be from ensemble forecasts or from a traditional forecast.
It usually does not make sense to mix statistics for different groups. The desired group to calculate statistics over can be specified in the “Specialized Plot Fixed Values” section. For a reliability diagram, the forecast variable (“FCST_VAR”) must be selected. In the example below, the forecast variable is “APCP_24_ENS_FREQ_gt12.700”. A single domain (category: “VX_MASK”, value: “EAST”) is chosen. If multiple domains or thresholds were chosen, the statistics would be a summary of all of those cases together, which may not always be desired.
Choose whether or not to display the reliability event histogram in the “Reliability Event Histogram” section. Event histograms allow the user to see how often the forecast falls within each probability bin. The sample sizes in each bin are typically different, and some may be too small for conclusions. They also allow the user to judge the sharpness of the forecasts.
There are two checkboxes in the “Reliability Event Histogram” section.
Skill line: The skill, or reliability, of a forecast is indicated by the proximity of the plotted curve to the diagonal skill line. The deviation from the diagonal gives the conditional bias. If the curve lies below the line, this indicates over-forecasting (probabilities too high); points above the line indicate under-forecasting (probabilities too low).
Reference line: This line (typically dashed) denotes the sample climatology or base rate, the frequency of the event.
Select what summary curve to display (if any) in the “Summary Curve” section.
Adjust the aggregation options, if desired, in the “Aggregation options” section.
Now enough information has been entered to produce a graph. To do this, click the “Generate Plot” button at the top of the METviewer window (this is in red text). Typically, if a plot is not produced, it is because the database selected does not contain the correct type of data. Also, it is imperative to check the data used for the plot by selecting the “R data” tab on the right hand side, above the plot area. The data from the database that is being used to calculate the statistics is listed in this tab. This tab should be checked to avoid the accidental accumulation of inappropriate database lines. For example, it does not make sense to accumulate statistics over different domains, thresholds, models, etc.
There are many other options for plots, but these are the basics.
13.4. Example
The reliability diagram shown below is for the probability of 24 hour precipitation with accumulations greater than or equal to 12.7 cm occurring over the eastern CONUS. In the figure the reliability curve has a positive slope, indicating that as the forecast probability of the event occurring increases, so does the likelihood of observing the event. The forecasts therefore have some reliability. However, the slope is much less than the diagonal, indicating conditional bias or a lack of reliability. In this example, when the forecast probability of precipitation is equal to 55% the actual chance of observing the event is closer to 35%.
The histogram shows the relative frequency with which the event has been predicted (typically over the reference period and at all grid points) with different levels of probability. In the example, the majority of forecasts predict low probabilities of precipitation (near the climatological probability of ~5%). The forecast system is also capable of predicting relatively high probabilities of the event (e.g. greater than 40%), but such forecasts are less common.
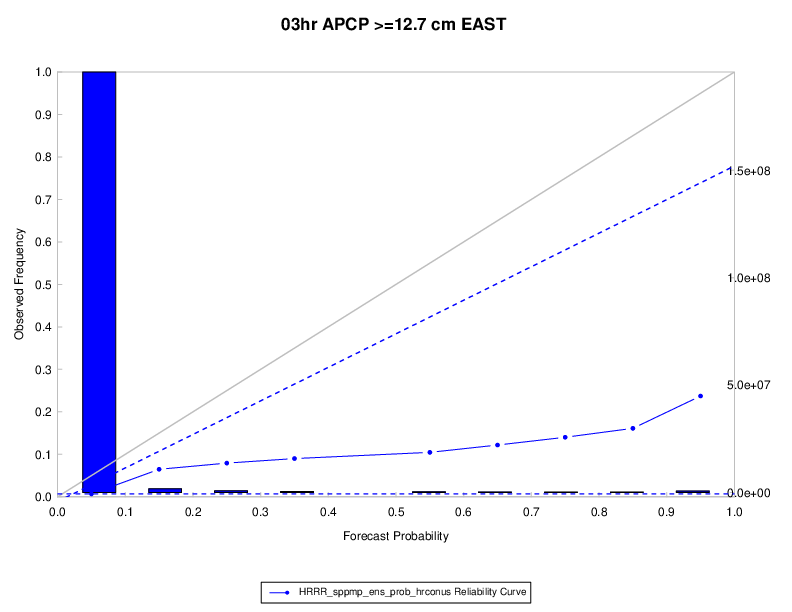
Figure 13.1 Example reliability (attributes diagram) with histogram of observation counts and bootstrap confidence intervals.
Here is the associated xml for this example. It can be copied into an empty file and saved to the desktop then uploaded into the system by clicking on the “Load XML” button in the upper-right corner of the GUI. This XML can be downloaded from this link: reliability_xml.xml.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<plot_spec>
<connection>
<host>mohawk</host>
<database>mv_hrrr_sppmp_test</database>
<user>******</user>
<password>******</password>
<management_system>mariadb</management_system>
</connection>
<rscript>/usr/local/R/bin/Rscript</rscript>
<folders>
<r_tmpl>/opt/vxwww/tomcat/webapps/metviewer//R_tmpl</r_tmpl>
<r_work>/opt/vxwww/tomcat/webapps/metviewer//R_work</r_work>
<plots>/d2/www/dtcenter/met/metviewer_output//plots</plots>
<data>/d2/www/dtcenter/met/metviewer_output//data</data>
<scripts>/d2/www/dtcenter/met/metviewer_output//scripts</scripts>
</folders>
<plot>
<template>rely.R_tmpl</template>
<series1>
<field name="model">
<val>HRRR_sppmp_ens_prob_hrconus</val>
</field>
</series1>
<plot_fix>
<field equalize="false" name="fcst_var">
<set name="fcst_var_0">
<val>APCP_03_ENS_FREQ_ge12.700</val>
</set>
</field>
<field equalize="false" name="vx_mask">
<set name="vx_mask_1">
<val>EAST</val>
</set>
</field>
</plot_fix>
<rely_event_hist>true</rely_event_hist>
<summary_curve/>
<add_skill_line>true</add_skill_line>
<add_reference_line>true</add_reference_line>
<agg_stat>
<agg_pct>true</agg_pct>
<boot_repl>1</boot_repl>
<boot_random_seed/>
<boot_ci>perc</boot_ci>
<eveq_dis>false</eveq_dis>
<cl_step/>
</agg_stat>
<tmpl>
<data_file>plot_20200921_172819.data</data_file>
<plot_file>plot_20200921_172819.png</plot_file>
<r_file>plot_20200921_172819.R</r_file>
<title>24hr APCP >=12.7 cm EAST </title>
<x_label>Forecast Probability</x_label>
<y1_label>Observed Frequency</y1_label>
<y2_label/>
<caption/>
<job_title/>
<keep_revisions>false</keep_revisions>
<listdiffseries1>list()</listdiffseries1>
<listdiffseries2>list()</listdiffseries2>
</tmpl>
<execution_type>Rscript</execution_type>
<event_equal>false</event_equal>
<vert_plot>false</vert_plot>
<x_reverse>false</x_reverse>
<num_stats>false</num_stats>
<indy1_stag>false</indy1_stag>
<indy2_stag>false</indy2_stag>
<grid_on>true</grid_on>
<sync_axes>false</sync_axes>
<dump_points1>false</dump_points1>
<dump_points2>false</dump_points2>
<log_y1>false</log_y1>
<log_y2>false</log_y2>
<varianceinflationfactor>true</varianceinflationfactor>
<plot_type>png16m</plot_type>
<plot_height>8.5</plot_height>
<plot_width>11</plot_width>
<plot_res>72</plot_res>
<plot_units>in</plot_units>
<mar>c(8,4,5,4)</mar>
<mgp>c(1,1,0)</mgp>
<cex>1</cex>
<title_weight>2</title_weight>
<title_size>1.4</title_size>
<title_offset>-2</title_offset>
<title_align>0.5</title_align>
<xtlab_orient>1</xtlab_orient>
<xtlab_perp>-0.75</xtlab_perp>
<xtlab_horiz>0.5</xtlab_horiz>
<xtlab_freq>0</xtlab_freq>
<xtlab_size>1</xtlab_size>
<xlab_weight>1</xlab_weight>
<xlab_size>1</xlab_size>
<xlab_offset>2</xlab_offset>
<xlab_align>0.5</xlab_align>
<ytlab_orient>1</ytlab_orient>
<ytlab_perp>0.5</ytlab_perp>
<ytlab_horiz>0.5</ytlab_horiz>
<ytlab_size>1</ytlab_size>
<ylab_weight>1</ylab_weight>
<ylab_size>1</ylab_size>
<ylab_offset>-2</ylab_offset>
<ylab_align>0.5</ylab_align>
<grid_lty>3</grid_lty>
<grid_col>#cccccc</grid_col>
<grid_lwd>1</grid_lwd>
<grid_x>listX</grid_x>
<x2tlab_orient>1</x2tlab_orient>
<x2tlab_perp>1</x2tlab_perp>
<x2tlab_horiz>0.5</x2tlab_horiz>
<x2tlab_size>0.8</x2tlab_size>
<x2lab_size>0.8</x2lab_size>
<x2lab_offset>-0.5</x2lab_offset>
<x2lab_align>0.5</x2lab_align>
<y2tlab_orient>1</y2tlab_orient>
<y2tlab_perp>0.5</y2tlab_perp>
<y2tlab_horiz>0.5</y2tlab_horiz>
<y2tlab_size>1</y2tlab_size>
<y2lab_size>1</y2lab_size>
<y2lab_offset>1</y2lab_offset>
<y2lab_align>0.5</y2lab_align>
<legend_box>o</legend_box>
<legend_inset>c(0, -.25)</legend_inset>
<legend_ncol>1</legend_ncol>
<legend_size>0.8</legend_size>
<caption_weight>1</caption_weight>
<caption_col>#333333</caption_col>
<caption_size>0.8</caption_size>
<caption_offset>3</caption_offset>
<caption_align>0</caption_align>
<ci_alpha>0.05</ci_alpha>
<plot_ci>c("none")</plot_ci>
<show_signif>c(FALSE)</show_signif>
<plot_disp>c(TRUE)</plot_disp>
<colors>c("#0000ffFF")</colors>
<pch>c(20)</pch>
<type>c("b")</type>
<lty>c(1)</lty>
<lwd>c(1)</lwd>
<con_series>c(1)</con_series>
<order_series>c(1)</order_series>
<plot_cmd/>
<legend>c("")</legend>
<y1_lim>c()</y1_lim>
<x1_lim>c()</x1_lim>
<y1_bufr>0.04</y1_bufr>
<y2_lim>c()</y2_lim>
</plot>
</plot_spec>